go design (三) map
golang 中 哈希表 map 的实现
哈希表 在 各种语言中有字典,映射 的称呼 ,本质上解决的是 key => value 键值对之间映射关系,因为其读写 O(1) 的复杂度,性能非常优秀,而被广泛使用。
哈希表 的设计原理
如何实现一个优秀的哈希表 ,关键点在于 哈希函数与冲突解决方案。理想的哈希函数 输出范围要大于输入范围,但实际上我们做不到,工程上优秀的 hash 函数,要保证输出均匀分布,复杂度接近 O(1), 而糟糕的 hash 函数 会导致输出不均匀分布,产生大量的冲突则复杂度可能会退化至 O(n)
解决冲突的两种方法
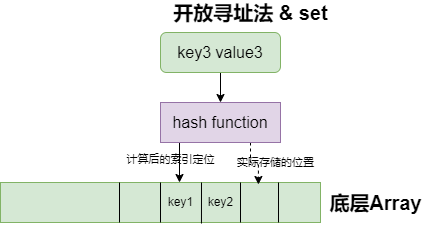
- 开放寻址法(依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中)
- 要求底层实现为数组
- 写入数据
- 向当前哈希表写入新的数据时,如果发生了冲突,就会将键值对写入到下一个索引不为空的位置。
- 读取数据
- 当需要查找某个键对应的值时,会从索引的位置开始线性探测数组,找到目标键值对或者空内存就意味着这一次查询操作的结束。
- 写入数据
- 开放寻址法中对性能影响最大的是装载因子,
- 装载因子 = 数组中元素的数量/数组大小
- 随着装载因子的增加,线性探测的平均用时就会逐渐增加,这会影响哈希表的读写性能。当装载率超过 70% 之后,哈希表的性能就会急剧下降,而一旦装载率达到 100%,整个哈希表就会完全失效,这时查找和插入任意元素的时间复杂度都是 O(n) 的,这时需要遍历数组中的全部元素,所以在实现哈希表时一定要关注装载因子的变化。
- 要求底层实现为数组
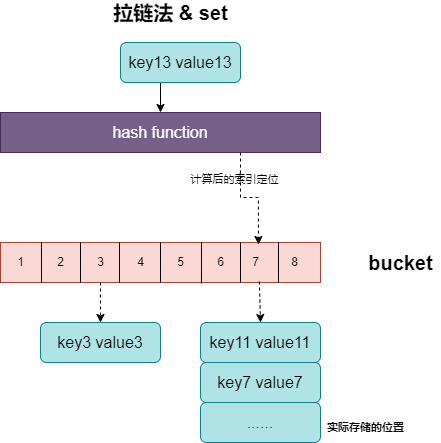
- 拉链法 (一般会使用数组加上链表,不过一些编程语言会在拉链法的哈希中引入红黑树以优化性能,我们可以将它看成可以扩展的二维数组)
- 拉链法会使用链表,数组作为哈希底层的数据结构
- 写入数据
- 先对key 进行hash 后取模,根据取模获取的值 去访问对应的桶
- 遍历当前桶中的链表
- 找到键相同的键值对 — 更新键对应的值;
- 没有找到键相同的键值对 — 在链表的末尾追加新的键值对;
- 写入数据
- 计算哈希、定位桶和遍历链表三个过程是哈希表读写操作的主要开销,使用拉链法实现的哈希也有装载因子这一概念:
装载因子 = 元素数量/桶数量- 拉链法的装载因子越大,哈希的读写性能就越差。理想情况下装载因子都不会超过 1。
- 当哈希表的装载因子较大时会触发哈希的扩容,创建更多的桶来存储哈希中的元素,保证性能不会出现严重的下降。
- 拉链法会使用链表,数组作为哈希底层的数据结构
- 对比两种方式,我们发现,拉链法通过引入中间层 bucket 来减少索引值不同情况下对于值存储的影响,而开放寻址法结构简单,不同 索引间会相互影响。所以市面上大多数的编程语言会使用拉链法来实现 map,包括 php golang …
golang 中 的 map 的实现
数据结构
golang使用了拉链法来实现哈希表, 以及多种数据结构来构成map[hmap主结构 ,bmap存储单元桶]
1 | |
- 根据源码的定义 ,我们得出下面的相关结构的关联关系
hmap->buckets->bmap->overflow->bmap
bmap详情tophash存储了键的哈希的高 8 位- 高 8 位会决定 key 到底落入桶内的哪个位置
keys values结构表明map的key value是 分开存储的,节省padding- 每一个
bmap最多装 8 个 key,(一个桶内最多有8个位置)- 随着哈希表存储的数据逐渐增多,我们会扩容哈希表或者使用额外的桶存储溢出的数据,
- 不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
- 哈希计算后,哈希结果是“一类”的 key 会落入同一个桶
初始化
字面量的方式创建 map
1
i := map[int]int{1: 1, 2: 2}- 底层默认还是使用
make去创建 然后初始化hmap的一些属性
- 底层默认还是使用
make创建map1
i := make(map[int]int)
读、写、删、扩容操作
读,写
hash计算- 会检测
cpu是否支持aes,如果支持,则使用aes hash,否则使用memhash key经过哈希计算后得到哈希值,共64个bit位
- 会检测
- 定位过程
- 计算它到底要落在哪个桶时,只会用到最后
B个bit位。 - 还记得前面提到过的 B 吗?如果 **
B = 5**,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32 10010111 | 000011110110110010001111001010100010010110010101010 │ 01010- 前 8 位 用于计算(
bmap.topbits) 在哪存放,后 B 位 用于 计算map会被分在 哪一个 bucket 内 - 比如
01010就去找 第 10 号的 bucket ,然后会 去 bucket 内 找到bmap.topbits这个数组 有没有10010111也就是151这个值- 如果 找到了 151 这个值 就用
bmap.topbits值的 key 去读取bmap.values[key]来获取正在的值,进行响应 - 如果没有找到 151 而
mapextra.overflow是存在的 ,那么就去去读取 额外的bmap去找
- 如果 找到了 151 这个值 就用
- 计算它到底要落在哪个桶时,只会用到最后
删除
- 删除使用
delete函数 ,此函数的唯一目的就是为了删除map中的数据 func delete(m map[Type]Type1, key Type)- 删除操作同样是hash =>定位 =>找到
bmap.topbits.key。找到后,对bmap.keys与bmap.values进行“清零”操作。
扩容
最理想的方式为 一个 bucket 装一个
key => value, 复杂度O(1)但是对于空间的消耗太大了golang中 一个 bucket 装 8个 key, 也是时间换空间的做法为了避免 key 都落在了同一个 bucket 里,导致 hash 表退化成链表效率降为 O(n)
- 我们用一个指标来衡量效率的情况,这就是 装载因子
loadFactor := count / (2^B)count为map的元素个数2^B为buckets的数量
扩容的条件
装载因子超过阈值,源码里定义的阈值是 6.5。
- 因为 一个 buckets 只有 8 个键位,装满则为 8,当然 装满了,也能往 overflow.bmap 里面继续放,也就是说负载因子可以大于8
- 当
loadFactor大于 6.5 的时候,就说明map的键位快要被用完了
tooManyOverflowBuckets 使用了太多溢出桶 而装载因子很小
- overflow bucket 数特别多,说明很多 bucket 都没装满。
- 解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。
- 这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。
- 结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升
扩容的执行
- 对于 装载因子大于 6.5 的情况,
- 将 B 的值 +1 实际值扩大两倍
- 比如 B 从 5 变成了 6,因此需要分流 原来通过 低5位来判定走哪一个bucket 的,现在看低 6 位决定 key 落在哪个 bucket。
- 这称为
rehash
- 将 B 的值 +1 实际值扩大两倍
- 而对于过多
overflow- 是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密
- 缺点为极端情况
- 插入 map 的 key 哈希都一样,就会落到同一个 bucket 里,
- 超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多。
- 移动元素其实解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了
O(n)
hashGrow()函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。- 真正搬迁 buckets 的动作在
growWork()函数中,而调用growWork()函数的动作是在mapassign()和mapdelete()函数中。 - 也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。
- 先检查
oldbuckets是否搬迁完毕,【具体来说就是检查oldbuckets是否为 nil】
- 对于 装载因子大于 6.5 的情况,
遍历与 map 的无序性
- 遍历的的主要操作在 源码
runtime/map.go mapiterinit函数实现 - 无序性主要体现在下面这段源码
1 | |
- 也就说 在引入 渐进式
rehash之后,你没法 直接对buckets.[]bmap进行遍历,必然要先去看看oldbuckets有没有迁移完,再去遍历新的buckets.[]bmap - 为了防止有人用
map的遍历顺序这个特性,开发人员 煞费苦心,直接引入了 随机数来引入无序性 - 那我们能不能 用
map的无序特点进行一些逻辑处理,我觉得不可行,从源码可以看出,无序仅限于入口的无序性,样本较少的情况下,这个随机性很弱。部分元素会出现一致性
关于 map 的几个小问题
map 可以 用 float 做 key 吗?
- 大前提是
map可以用什么类型当key- 只要是 可以进行
==作为判定的 类型都能当作key slice,map,functions这几个类型不能当作key1
2
3
4
5
6
7m := make(map[float64]int)
m[2.4] = 2
f1 := 2.4
f2 := 2.4000000000000000000000001
fmt.Println(f1 == f2) // true
fmt.Println(m[2.4000000000000000000000001]) // 2
- 只要是 可以进行
- 所以 用
float会存在隐患,不建议使用
map 可以边遍历 边删除/边写入 吗?
可以,但是
map不是线程安全结构,同时读写会导致 panic , 如果在遍历,赋值,查找,删除的过程中,检测写标准存在就会 panic1
2
3
4
5
6
7
8//runtime/map_fast64.go
// 检测是否在读写
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 设置 写入位
h.flags &^= hashWriting遍历并不是顺序的中途写入值与删除值 ,可能会被遍历出来,导致未知的结果
可以 使用
sync.Map或者 读写锁sync.RWMutex来处理 不过不建议 对于 时刻变化的 map 进行遍历,遍历的结果是不准确的
如何比较 两个 map 是否相等
两个
map不能进行比较invalid operation: m1 == m2 (map can only be compared to nil)map只能 判断是否为nil也就是map == nil1
2
3
4
5
6
7
8m1 := make(map[int]int)
var m2 map[int]int
s1, _ := json.Marshal(m1)
s2, _ := json.Marshal(m2)
fmt.Println(string(s1)) // {}
fmt.Println(string(s2)) // null
fmt.Println(m1 == nil) // false
fmt.Println(m2 == nil) // true如果要判断两个
map是否真的相等,只能 遍历去判断 或者json转换后的结果进行判定
